
Title: Software Design X-Rays
Author: Adam Tornhill
Published: 2018 by The Pragmatic Bookshelf
Pages: 274
My rating: 5/5
Goodreads.com rating: 4.25 (8 ratings)
Prerequisites: Knowledge about programming, static code analysis, technical debt, and version control
Whom I recommend: Developers, architects, and their managers
This was a surprisingly good book. It is about how to detect bad code from a code base with the help of code’s history from git or other version control. I was really surprised how simple things and techniques book uncovered, even if I thought code quality is one of my strengths. The key point is the time. We shouldn’t do just static analysis from our current code but analyze how our code has lived and progressed. I will cover some interesting things from the book in this blog post.
Questioning Technical Debt
Most of the developers are know what is technical debt. Usually, we define it as a quick and dirty solution to make something to work quickly. And because it is bad quality, we pay a debt for it when trying to understand it (takes a lot of time to understand) and make further changes to it (difficult to make changes and we easily deepen technical debt).
Before reading the book I thought simply that bad code should be fixed. Others prefer not to change working code (“if not broken don’t fix it”). Tornhill advice something between these: fix the important code and don’t fix the unimportant code. His definition of technical debt is:
Technical debt is code that’s more expensive to maintain than it should be. That is, we pay an interest rate on it.
After reading the book I have changed my mind about technical debt. All bad code isn’t technical debt. It depends on how much we have to work with it.
It’s not technical debt unless we have to pay interest on it, and interest rate is a function of time.
We can think that every bad code (traditional technical debt) has an interest rate. If the interest rate is low, we even shouldn’t fix the code. But if the interest rate is high it will become expensive over time because there will be compound interest.
How we can analyze the interest rate? Tornhill introduces really interesting code analysis which we can make from the code history. And that history we can analyze from version control, for example, git.
Our version control data is an informational gold mine.
Behavioral Code Analysis
So how can we find bad code that we should fix and ignore those that doesn’t matter (even if the code is really hard to understand)? How can we measure interest rates of our code?
Tornhill uses behavioral code analysis for this. It is a bit different point of view than static code analysis that we are familiar with. Static code analysis is what we do when we see the code and judge it as bad code and immediately start to fix it. Behavioral code analysis uses version control data to analyze code. It includes also time for the analysis. It is a “dynamic code analysis”.
Hotspot Analysis
We should focus our attention on the code that is frequently changed because according to Tornhill files with high change frequencies suffer quality problems. Below picture was taken from the book. It represents typical code change frequencies in a code repository. Tornhill showed the same graph from few open source repositories and they were practically identical! He has made many code analysis and he says every code base represents this same pattern.
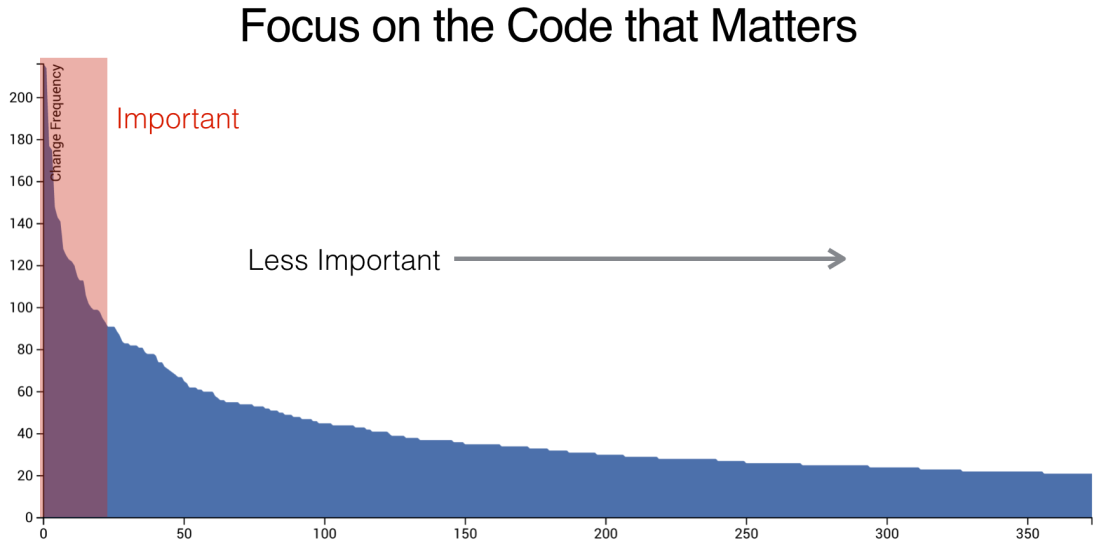
It was surprising to me that we work mostly just with a few code files. This is something we can’t know without behavioral code analysis from version control data. Should we rush to fix most changed code files? The answer is no because all code isn’t equal. Tornhill tells a simple example why. Some file can change frequently just because we increase a version number in a single line text file. In turn, there is a huge difference correcting a bug in a module with 5000 lines of C++ littered with tricky, nested conditionals. We can further analyze those important code files: which are most important of most important? We need to add a complexity dimension.
Luckily there is really simple programming language neutral complexity metric: the number of lines of code (another really simple thing I didn’t realize before reading the book). By combining change frequency and complexity (number of lines of code) we can detect hotspots from our code. Tornhill calls this hotspot analysis.
With hotspot analysis, we can detect most problematic files, those that are most complex and frequently changed, and refactor them. It tells us which files we should focus our refactoring to lower our most high technical debt interest rate.
Hotspot Analysis in Function Level
Tornhill goes deeper with the hotspot analysis: it is more efficient if you do hotspot analysis in function level rather than file level. Find functions that are most complex (measured by lines of code) and changed frequently and focus to repair them.
It doesn’t help a much if hotspot analysis tells that 5000 lines long MyBigClass.cs is most problematic. It is difficult to know where to begin if the file is really long! But we can do hotspot analysis also in function level. Then analysis tells hotspot functions and we have a better idea where to start refactoring. Hotspot analysis of functions tells same as with files: which functions are longest ones and most frequently changed and thus are potential high interest rate functions.
You can read more about hotspot analysis also from Adam Tornhill’s web page. There can be found nice visualizations of hotspot maps.
The big win with a hotspot analysis is that it lets us minimize our manual efforts while ensuring a high probablity that we focus on the right parts of the code.
Find Surprises with Change Coupling Analysis
Another really interesting behavioral code analysis Tornhill explains is the change coupling:
Change coupling means that two (or more) files change together over time.
Practically if codes A and B are usually changed together in the same commit, there is change coupling between them. We can do interesting analysis from change coupling and even find code with a really high interest rate that we won’t usually find.
Tornhill writes about surprises, which are one of the most expensive things we can put into a software architecture. What he means by surprise are surprising change patterns. For example, if a change to a Patient class requires also change to an Organization class, that is surprising change pattern. Intuitively we won’t know that they have that kind of relationship. If there is that kind of surprise, one day someone changes only one of them and strange errors start to occur.
Maintenance programmer coming after us is likely to suffer the consequences of any surprising change pattern we’ve left in the design. Software bugs thrive on surprises.
Change coupling isn’t always a bad thing. For example, there should be change coupling between unit test and code under test. It comes bad when there is a surprise in change coupling, really bad.
Even if we find change coupling between files, it may be hard to act on that information, says Tornhill. But if we do change coupling analysis in function level (like we did with hotspots), we will know surprising change patterns between functions and we know better what to fix.
Refactoring Techniques
There were few new refactoring techniques in the book for me. Those try to fix hotspots and surprising change couplings.
Proximity Refactoring
This is a simple technique to remove surprise from change coupling: move related code together. It is easier to detect change coupling when related functions are in a row.
The main advantage of a proximity refactoring is that it carries low risk.
When writing a new code we usually try to put related functions in a row. But when time goes by, there appear new functions in the wrong places. We often forget proximity refactoring even if it is really important.
Splinter Pattern
Splitting hotspot into parts is called splinter pattern. It is easier to maintain many smaller pieces of code than having a group of developers work on one large piece of code, says Tornhill.
At first, splinter pattern sounds peace of cake but it isn’t, at least if the hotspot is big and there are many programmers. Reason for difficulty is that hotspot changes constantly by many developers, and thus it is difficult to refactor. And also because it is large, it makes other challenges to refactor. Splitting it first into two parts etc. helps to refactor it or use facade pattern while refactoring.
Hotspots are painful and they keep getting more complex all the time, and its already high interest rate keeps growing:
The hotspot has many reasons to change. This leads to a downward spiral where every interesting new feature has to touch the hotspot code, which reinforces its change rate by adding yet another responsibility.
We should fix hotspots before they get too big.
Conclusion
“This is really interesting and simple. Why didn’t I realize this earlier?”, this repeated many times while reading this book. Many things in the book were new for me, even if I thought I know a lot about code quality. Behavioral code analysis is a more effective way to analyze our code than static code analysis. It reveals where we really should start to fix our code quality and where are surprising change couplings in our code base.
I only mentioned a couple most interesting things from the book. For example, Tornhill introduced CodeScene tool and git commands to do these analyses that I skipped here. You can have quick look for CodeScene’s reports in this article in Tornhill’s web page: Software (r)Evolution – Part 1: Predict Maintenance Problems in Large Codebases
Following talk is practically an abstract of this book: GOTO 2017 • A Crystal Ball to Prioritize Technical Debt • Adam Tornhill.
I warmly recommend developers, architects, and their managers to read this book and get a new view on your code base.

There are several things what are needed to consider that code is good. One is efficiency under heavy workload. I’ve seen that kinda of adapter which collects all updates patients in a day to file every couple of minutes. And then sends and loads them to other system. Code might be good and run nicely in low workload. But think about situation that there are tens of thousands updated records some day, how many updates this will make to target system. Every couple of minute all those updates are sent to target system. This will slow target system and fill database archive logs. I mean, that it’s not so easy to say code is good until it’s run in real production environment with heavy load. 🙂
LikeLike
True, there are many dimensions for what is good code. And definitely good code has to run under production. Maybe I will write “What is good code?” blog post some day (inspired by this comment, thanks!).
Ps. That adapter sounds too familiar ‘=).
LikeLike